Felix Halim,
Roland H.C. Yap,
Yongzheng Wu
[ ICDCS11 Paper ]
Abstract
Maximum-flow algorithms are used to find spam
sites, build content voting system, discover communities, etc.,
on graphs from the Internet. Such graphs are now so large that
they have outgrown conventional memory-resident algorithms.
In this paper, we show how to effectively parallelize a max-flow
algorithm based on the Ford-Fulkerson method on a cluster
using the MapReduce framework. Our algorithm exploits the
property that such graphs are small-world networks with low
diameter and employs optimizations to improve the effectiveness
of MapReduce and increase parallelism. We are able to
compute max-flow on a subset of the a large social network
graph with 411 million vertices and 31 billion edges using a
cluster of 21 machines in reasonable time
Background and Motivation
Nowdays, the real-world graphs (such as WWW, Social Networks, etc.) have grown very large.
For example, a Facebook graph with 700 million users where each user has 130 friends on average,
requires a storage space of 700 * 10^6 * 130 * 4 bytes = 364 Gigabytes just to store the relationships alone.
Even if we have a super computer with Terabytes of memory, it is unclear whether running the best
maxflow algorithm on such large graph can be practical
(the current best maxflow algorithm has a complexity of at least quadratic in respect of the number of vertices).
In this paper, we investigate the feasibility of computing maxflow on a very large small-world network (SWN) graph.
One of the property of a SWN graph is that it has a very small (expected) diameter
(the shortest path length between any two vertices in the graph is expected to be small).
This allows us to develop variants of the Ford-Fulkerson method to compute maxflow effectively for SWN graphs.
Since we are dealing with a type of graph which size is far larger than a single machine memory capacity,
we took an appoach to distribute the graph into several machines in a cluster to be processed in parallel.
Currently, MapReduce has become the facto standard to store, manage, and process very large datasets on a cluster of thousands of commodity machines.
We designed an developed our maxflow variants to work on top of the MapReduce framework.
The Challenges and Approach
The classical maxflow algorithms were designed under assumption that the entire graph is small enough fit into main memory.
Such algorithms are not directly applicable to run on distributed systems (such as MapReduce framework) since it require a global view of the entire graph.
On the other hand, the existing distributed maxflow algorithm based on the Push-Relabel algorithm, while it can work in local manner, is too reliant on heuristics to push the flow.
A wrong push can cause a very large number of MR rounds spent circling around the flow, thus is not suitable for MapReduce.
However, in a system where performing one round is cheap (using Bulk-Synchronous Parallel model), Push-Relabel should perform much better.
We decided to develop maxflow variants based on the Ford-Fulkerson method.
With assumption that the graphs being processed have small diameter,
we transformed the naive (sequential) Ford-Fulkerson method into a highly parallelizable MR algorithm variants by
finding augmenting paths incrementally, bi-directional search, and multiple excess paths.
In the next subsections we illustrate the inner working of the naive Ford-Fulkerson method and the variants.
Notice the number of MR rounds required for each variant (the lower the better).
We combined these variants together to form an effective maxflow algorithm on MR framework which we called FF1MR.
The Naive Ford-Fulkerson Method
The naive Ford-Fulkerson method works by repeatedly find an augmenting path in the current residual graph and augment it:
while true do
P = find an augmenting path in the current residual graph Gf
if (P does not exist) break
Augment the flow f along the path P
The Ford-Fulkerson method does not dictate how to find an augmenting path.
The naive way to find it is to use Breadth-First Search (BFS).
The complexity of this method is O(|f*| D) rounds, where |f*| is the maxflow value and D is the diameter of the graph.
Note that in MR algorithms, we measure the complexity in terms of number of MR jobs (or rounds) performed.
Below is an illustration on how the maxflow can be found using this way.
Finding Augmenting Paths Incrementally
An improvement from the previous method is to incrementally find the augmenting paths.
That is, we don't re-start the BFS from scratch everytime an augmenting path is found.
Instead, we continue the work from the previous round's result by updating parts of the graph
and only destroy/remove the results that aren't fruitful.
The incremental finding of augmenting paths reduces the complexity to be far lower than O(|f*| D) rounds
since an augmenting path may arrive continuously every subsequent rounds.
We expect the complexity to be O(|f*|) rounds.
Bi-Directional Search
Bi-directional search is a two-way search: one originates from the source vertex s and the other is from the sink vertex t.
This doubles the utilization of work per round, so that more work can be done each round.
This also effectively halves the number of rounds required to complete the maxflow.
We allow more than one augmenting path to be accepted per round.
The expected complexity of this variant is O(|f*| / A) rounds, where A is the average number of augmenting paths accepted per round.
Below is the illustration of the bi-directional search variant, improving the incremental updates variant.
Multiple Excess Paths
When an augmenting path is found and augmented, many vertices will lose its excess path if they are conflict with the augmenting path.
To prevent vertices to lose all of its excess paths, we allow each vertex to store K excess paths so that
even though large number of augmenting paths are augmented, many of the vertices will still be active and continue to give
streams of new augmenting paths every round.
Among all variants described above, this multiple excess paths variant gives the most decrease in the number of rounds.
The complexity of these variants altogether is O(|f*| / A) where A is the number of augmenting paths accepted per round.
The value of A is very large such that the complexity becomes very close to O(D).

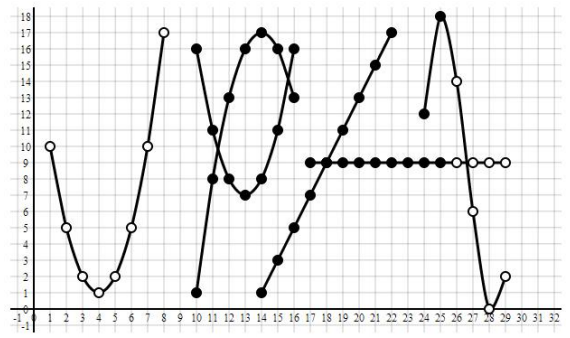
The experiment result above shows that the number of excess path stored in each vertex (K) have significant impact
in computing maxflow of two random vertices s and t
on a social network subgraph (FB1) with 21 million vertices and 112 million edges.
The more the K the less the number of MR rounds required.
On a very large value of K, the number of rounds becomes close to the diameter of the graph.
MapReduce Optimizations
MapReduce is a general purpose framework.
It is not necessarily the best framework to process graph-based data.
In this section we describe our MR optimizations to work around the limitations of MR in processing graph-based data.
We implemented each optimization into a variant of our FF1MR algorithm:
FF2MR : Stateful Extension for MR
When there are a lot of augmenting paths found in one round, we must have a (single threaded) worker that decides
which augmenting paths to be accepted and which are to be rejected. In FF1, this decision is made by one of
the reducers that is responsible for vertex t. The larger the number of augmenting paths, the longer that reducer need to run.
This can cause a convoy effect where the other reducers are already finish but the reducer which process vertex t lags behind.
This lead us to create an extension for MR, that is a dedicated worker outside MR which job is to process
augmenting paths that are generated in each round by the reducers.
This has advantages that the dedicated worker can start working as soon as it receives augmenting paths from the reducers.
It doesn't need one extra step to send augmenting paths (as messages) to vertex t which wastes one MR round.
This stateful extension solves the bottleneck of FF1MR.

The improvement it brings is significant.
FF2MR improvement is up to 3.41 times faster for FB4 and 1.85 times faster for FB1.
FF3MR : Schimmy method
Schimmy method is an MR design pattern for processing graph-based data.
The improvement is more apparent for larger graph FB4 (1.74 times) and lesser for smaller graph FB1 (1.25 times).
FF4MR : Avoid Object Instantiations
This is a common optimizations. The improvement is around 1.16 - 1.41 times.
FF5MR : Storage Space vs. number of rounds and communication costs
The last but not least optimization is to avoid sending messages (as intermediate records) each round by sacrificing some storage space (used as flags).
We can also sacrifice storage space by storing maximum number of excess paths (set K = 5000) to reduce the number of rounds.
We avoid sending delta updates as messages (as intermediate records) if we can re-compute the delta in the reducers.

We found a high correlation between the number of shuffled bytes and the runtime and in this variant,
we try to minimize the number of shuffled bytes as much as possible.
The reduce shuffle bytes depends on the number and the size of the intermediate records.
The experiment above shows the number of bytes shuffled for each variant (from FF1 to FF5).
FF1 is the worst since it sends all the augmenting paths found in the current round to vertex t as messages.
Therefore there from round #4 to #8 the reduce shuffle bytes is high.
FF2 uses the external worker to immediately process the augmenting paths, therefore the reduce shuffle bytes for round #4 to #8 is small,
however, it grows afterwards since every active vertices always re-send its excess path to its neighbors.
FF3 avoid the master graph to be shuffled, so it is a consistent improvement over FF2.
FF4 doesn't reduce the shuffled bytes, hence not shown here.
FF5 sets the K to maximum and prevent redundant messages (by recomputing or by flag).
FF5 manages to keep the shuffled bytes small and it is the best of our MR variants.
Scalability
We tested our FF5MR variant for very large flow value on a very large social network subgraph (FB6) with 411 million vertices and 31 billion edges.
To create a very large flow, we combine w = 128 random vertices and create a super source vertex s, and similarly with the super sink t.
The flow between the super source and the super sink can be up to 128 * 5000 = 640,000.

The experiment shows that even for such large maxflow values, the number of rounds required to compute the maxflow stay small (around 7 to 8 rounds).
This suggest that the approaches that we've put in FF1MR are effective in minimizing the number of rounds.
The runtime increases linearly while the maxflow value increases exponentially.
This shows the scalability of our FFMR in handling a very large maxflow value.
Another scalability test is in terms of graph size and number of machines (from 5 to 20 machines).
We plot the runtime and number of rounds required to compute maxflow on several subgraphs (FB1 to FB6).
We also created the super source and the super sink for w = 128 (the vertices are randomly chosen in the subgraph).
We also plot the best case scenario of running a single Breadth-First Search on each subgraph.

The experiment shows that our best variant, FF5MR, is only a constant factor slower than a BFSMR!
The maxflow value is writen under the subgraph name (FB1 to FB6).
If we see the graph in terms of number of edges processed per second:

The experiment shows that the larger the graph, the higher the number edges processed per second.
This may mean several things: the larger the graph, the smaller its diameter and the more robust the graph (that is, despite the large number of deletion of edges in the residual graph, the graph still maintain small diameter).
Conclusion and Future Work
We developed what we believe to be the first
effective and practical max-flow algorithms for MapReduce.
While the best sequential max-flow algorithms have around
quadratic runtime complexity, we show it is still possible
to compute max-flow efficiently and effectively on very
large real-world graphs with billions of edges. We achieve
this by designing FFMR algorithms that exploit the small
diameter property of such real-world graphs while providing
large amounts of parallelism. We also present novel MR
optimizations that significantly improve the initial design
which aim to minimize the number of rounds, the number
of intermediate records, the size of the biggest record. Our
optimizations also exploit tradeoffs between space needed
for the data and number of rounds. Our preliminary experiments
show a promising and scalable algorithm to compute
max-flow for very large real-world social network sub-graphs.
We still see several rooms for improvement such as optimizing the last few rounds as well as giving an approximation of a maxflow value to get faster runtime.
We also see the need to benchmark with custom build Graph framework which optimizes the memory management in the case where the entire graph fit to the total memory capacity of a cluster of machines. A comparison with the Push-Relabel algorithm implemented on a Bulk-Synchronous Parallel would be a good direction as well.